
Generalization in robotic manipulation remains a critical challenge, particularly when scaling to unseen environments with limited demonstrations. This paper introduces CAGE, a novel robotic manipulation policy designed to overcome these generalization barriers by integrating a causal attention mechanism. CAGE utilizes the powerful feature extraction capabilities of the DINOv2 foundation model, combined with LoRA fine-tuning for efficient image encoding. The policy further employs a causal Perceiver for compressing tokens and a diffusion-based action prediction head with attention mechanisms to enhance task-specific fine-grained conditioning. With as few as 50 demonstrations from a single training environment, CAGE achieves robust generalization across diverse visual changes in objects, backgrounds, and viewpoints. Extensive experiments validate that CAGE significantly outperforms existing state-of-the-art RGB/RGB-D approaches in various manipulation tasks, especially under large distribution shifts. In similar environments, CAGE offers an average of 42% increase in task completion rate. While all baselines fail to execute the task in unseen environments, CAGE manages to obtain a 43% completion rate and a 51% success rate in average, making a huge step towards practical deployment of robots in real-world settings.

CAGE is composed of three parts: (1) observation images are passed to DINOv2 image encoder (LoRA fine-tuning) to obtain stacks of observation tokens. (2) The concatenated observation tokens are compressed by Causal Observation Perceiver. The learned tokens, along with the timestep embeddings serve as the conditioning for noise prediction. (3) The Attn-UNet takes as input a sequence of noisy actions prefixed by proprioceptions and outputs noise estimation, following standard diffusion procedure.

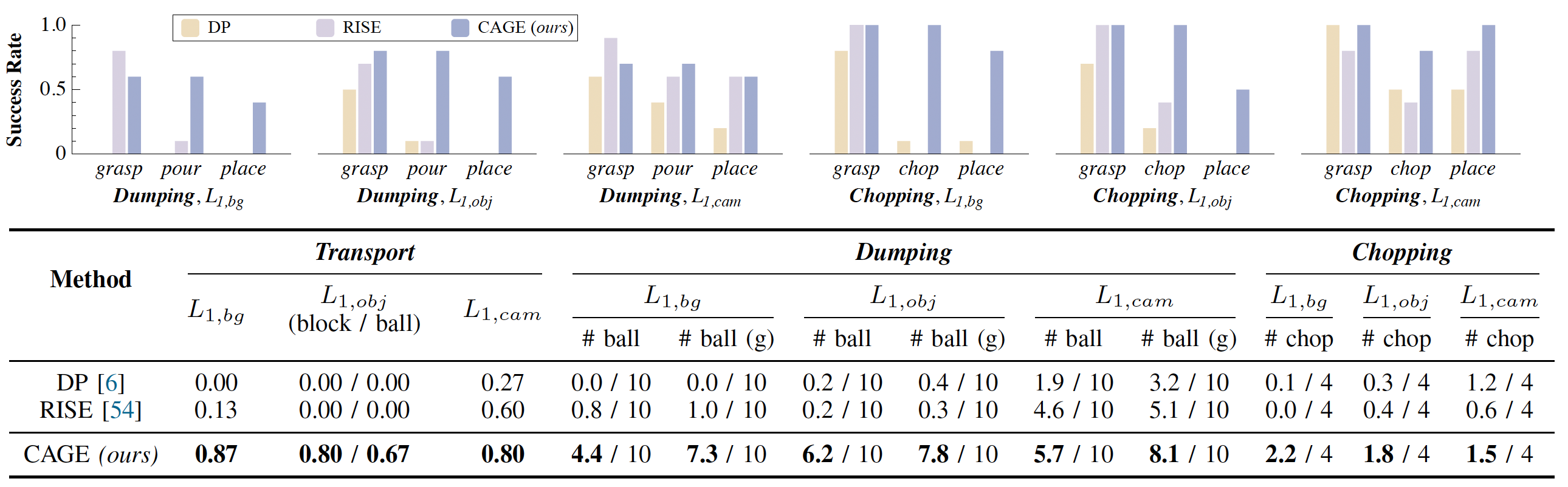
To evaluate the generalization ability of the policy, we design 3 tasks with generalizable skills: Transport, Dumping and Chopping. With a special focus on generalization, our tasks are designed at the skill level, so we do not impose strict requirements on the objects, and they can be substituted with any similar items. We evaluate CAGE and various baselines (2D: Diffusion Policy (DP); 3D: RISE) on these tasks.
Each policy is evaluated through three levels of distribution shifts to fully assess its generalizability in real-world:
In the following sections, all the videos are autonomous rollouts of the CAGE policy with 10Hz parallel execution.


CAGE Rollouts.
RISE Rollouts.
Diffusion Policy (DP) Rollouts.
Complete Evaluation Video for Transport in unseen environment.
We also show some failure cases in L1 and L2 evaluations of the CAGE policy here. Most failures are due to inaccuracies in predicted actions, which can be amplified and accumulated by real-time execution with relative action representation.
@article{
xia2024cage,
title = {CAGE: Causal Attention Enables Data-Efficient Generalizable Robotic Manipulation},
author = {Xia, Shangning and Fang, Hongjie and Lu, Cewu and Fang, Hao-Shu},
journal = {arXiv preprint arXiv:2410.14974},
year = {2024}
}
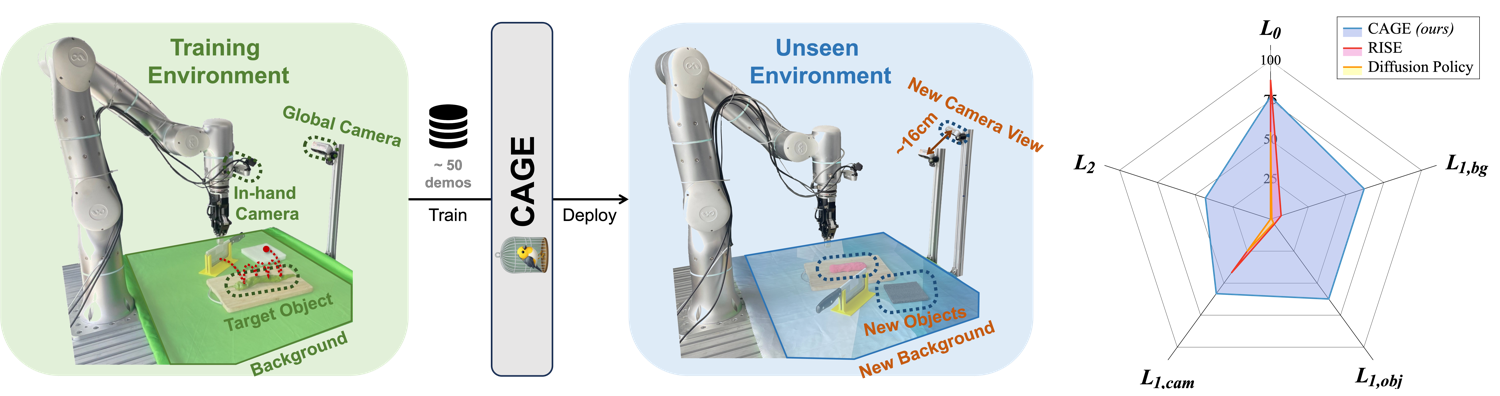 CAGE is a data-efficient generalizable robotic manipulation policy. With approximately 50 mono-distributed demonstrations, CAGE can effectively complete the task in test environments with different levels of distribution shifts: training environment (L0), similar environment (L1), and unseen environment (L2). Experiments demonstrate that CAGE generalizes well to L1 and L2 environments and significantly outperforms prior works.
CAGE is a data-efficient generalizable robotic manipulation policy. With approximately 50 mono-distributed demonstrations, CAGE can effectively complete the task in test environments with different levels of distribution shifts: training environment (L0), similar environment (L1), and unseen environment (L2). Experiments demonstrate that CAGE generalizes well to L1 and L2 environments and significantly outperforms prior works.